
Section 25 客户端存储
js为什么会涉及到客户端存储呢?
目标:将不常更新、且相对公用的数据存储在客户端中,减少与服务端的交互,提高整体的性能。
cookie
原始目标: 要求HTTP头部包含会话信息。
cookie具有局限性
浏览器级别的局限性:
- 不超过300个cookie
- 每个cookie不超过4096字节
- 每个域不超过20个cookie
- 每个域不超过81920字节。
域级别的局限性:
| 浏览器 | 每个域的cookie限制 |
|---|---|
| Edge | 不超过50 |
| Firefox | 不超过150个 |
| Opera | 不超过180个 |
| Safari和Chrome | 没有硬性限制 |
浏览器对于cookie的过限处理:
如果cookie总数超过了单域上限,浏览器会删除之前设置的cookie。
- Opera的处理策略是最少使用删除原则
- Firefox是随机删除原则
cookie构成
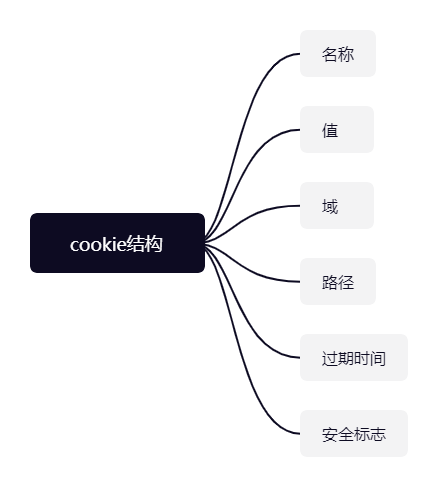
-
名称:cookie的唯一可标识,且不区分大小写,cookie名称必须经过URL编码。
-
值:存储在cookie里的字符串值,值也必须经过URL编码
-
域:cookie的有效域。发送到这个域的所有请求都会包含对应的cookie
-
路径:请求URL中包含这个路径才会把cookie发送到服务器。
-
过期时间:表示何时删除cookie的时间戳。
删除策略:
- 默认会话结束后删除cookie
- 定时删除cookie
-
安全标记:设置之后,只在使用SSL安全连接的情况下才会把cookie发送到服务器。例如:https://www.test.com会发送cookie,而请求http://www.wrox.com则不会。
js的cookie
js中的cookie接口只有*BOM(Brower Object Model)*的document.cookie
取值过程会获取页面中所有的有效cookie字符串(根据域、路径、过期时间和安全设置),以分号分隔。
子cookie
子cookie的机制实际上是利用cookie的机制,将一连串的cookie信息编码成字符串,给cookie的其中一个键上。
使用cookie的注意事项
叫做HTTP-only的cookie。Http-only可以在浏览器设置,也可以在服务器设置。但只能在服务器上读取。这种cookie值js无法读取。
注意:因为所有cookie都会作为请求头部由浏览器发送给服务器,所以在cookie种保存大量信息可能影响特定域浏览器请求的性能。保存的cookie越大,请求完成的时间就越长。即使浏览器对cookie大小有限制,最好还是尽可能只能保存必要信息,避免性能问题。
对cookie的限制及其特性决定了cookie并不是存储大量数据的理想方式。
Web Storage
目标:
Web Storage的规范目标:
- 提供在cookie之外的存储会话数据的途径
- 提供跨会话持久化存储大量数据的机制
Storage类型
目标:可用于保存键值对数据,直到达到存储控件上限(取决于浏览器)。
Storage实例的特征方法:
- clear():删除所有值,注意在FireBox中没有实现。
- getItem(name):取得给定name的值。
- key(index):取值给定数值位置的名称。
- removeItem(name):删除给定name的键值对。
注意:
- 通过 length 属性可以确定 Storage 对象中保存了多少名/值对。
//方法一
for (let i = 0, len = sessionStorage.length; i < len; i++){
let key = sessionStorage.key(i);
let value = sessionStorage.getItem(key);
console.log(key,value);
}
//方法二
for (let key in sessionStorage){
let value = sessionStorage.getItem(key);
console.log(key,value);
}
- Storage 类型只能存储字符串。非字符串数据在存储之前会自动转换为字符串。注意,这种转换不能在获取数据时撤销。
sessionStorage对象
sessionStorage 对象只存储会话数据,这意味着数据只会存储到浏览器关闭。这跟浏览器关闭时会消失的会话 cookie 类似。存储在 sessionStorage 中的数据不受页面刷新影响,可以在浏览器崩溃并重启后恢复。(取决于浏览器,Firefox 和 WebKit 支持,IE 不支持。)
localStorage对象
要访问同一个 localStorage 对象,页面必须来自同一个域(子域不可以)、在相同的端口上使用相同的协议。
注意:
localStorage和sessionStorage的区别,loaclStorage中的数据会保留到通过js删除或者用户清楚浏览器缓存。localStorage 数据不受页面刷新影响,也不会因关闭窗口、标签页或重新启动浏览器而丢失
存储事件
每当 Storage 对象发生变化时,都会在文档上触发 storage 事件。使用属性或 setItem()设置值、使用 delete 或 removeItem()删除值,以及每次调用 clear()时都会触发这个事件。这个事件的事件对象有如下 4 个属性。
- domain:存储变化对应的域。
- key:被设置或删除的键。
- newValue:键被设置的新值,若键被删除则为 null。
- oldValue:键变化之前的值。
注意:
对于 sessionStorage 和 localStorage 上的任何更改都会触发 storage 事件,但 storage 事件不会区分这两者。
IndexedDB
Indexed Database API简称IndexedDB,浏览器中存储结构化数据的解决方案。
IndexedDB的设计完全异步,故通常是以请求的形式执行,这些请求会异步执行,产生成功的结果或错误。
常利用onerror和onsuccess事件处理程序来确定输出。
数据库
声明一个indexedDB数据库
-
调用**indexedDB.open()**方法,第一个参数是数据库名称,第二个参数是版本号
**注意:**如果给定名称的数据库已存在,则会发送一个打开它的请求;如果不存在,则会发送创建并打
开这个数据库的请求
-
通过添加onerror和onsuccess事件去监听打开失败或者打开成功
let db, request, version = 1; request = indexedDB.open("admin", version); request.onerror = (event) => alert(`Failed to open: ${event.target.errorCode}`); request.onsuccess = (event) => { db = event.target.result; };
对象存储
IndexedDB使用对象存储而不是表,并且单个数据库可以包含任意数量的对象存储。当一个值存储在对象存储库中时,它就与一个键相关联。根据对象存储是使用密钥路径(Key Path)还是密钥生成器(Key Generator),有几种不同的方式可以提供密钥。
下述表格多种以提供键的方式:
| Key Path(keyPath) | Key Generator(autoIncrement) | Description |
|---|---|---|
| N | N | 这个对象存储可以保存任何类型的值,甚至是像数字和字符串这样的基本值。每当要添加新值时,必须提供单独的键参数。 |
| Y | N | 这个对象存储只能保存JavaScript对象。对象必须具有与Key Path同名的属性。 |
| N | Y | 这个对象存储可以保存任何类型的值。键是自动生成的,如果您想使用特定的键,也可以提供单独的键参数。 |
| Y | Y | 这个对象存储只能保存JavaScript对象。通常生成一个键,并且生成的键的值存储在与Key Path同名的属性中的对象中。但是,如果这样的属性已经存在,则使用该属性的值作为键,而不是生成新键。 |
-
准备数据
// 创建用户对象数组 const customerData = [ { ssn: "444-44-4444", name: "Bill", age: 35, email: "bill@company.com" }, { ssn: "555-55-5555", name: "Donna", age: 32, email: "donna@home.org" }, ]; -
创建IndexedDB存储我们的数据
const dbName = "the_name"; const request = indexedDB.open(dbName, 2); request.onerror = (event) => { // 处理数据库打开的异常处理 }; request.onupgradeneeded = (event) => { const db = event.target.result; //创建一个对象存储保存用户信息,并通过ssn作为键路径(默认为唯一索引) const objectStore = db.createObjectStore("customers", { keyPath: "ssn" }); // 将name作为对象存储的一个查询索引,目标是为了通过name去筛选用户 // 因为用户名是可重复的,所以我们唯一索引属性不能为true objectStore.createIndex("name", "name", { unique: false }); // Create an index to search customers by email. We want to ensure that // no two customers have the same email, so use a unique index. // 将email作为对象存储的一个查询索引,目标是为了通过email去筛选用户 // 因为邮箱是不可重复的,所以我们唯一索引属性设置为true objectStore.createIndex("email", "email", { unique: true }); // 使用交易的oncomplete 来保证对象存储的创建在数据添加之前已经完成 // 事务处理 objectStore.transaction.oncomplete = (event) => { // Store values in the newly created objectStore. // 将用户信息存储到一个创建好的对象存储当中。 const customerObjectStore = db .transaction("customers", "readwrite") .objectStore("customers"); customerData.forEach((customer) => { customerObjectStore.add(customer); }); }; };注意:
onupgradenneeded是唯一可以更改数据库结构的地方。在其中,您可以创建和删除对象存储,构建和删除索引。
事务:
const transaction = db.transaction(["customers"], "readwrite");
// Note: Older experimental implementations use the deprecated constant IDBTransaction.READ_WRITE instead of "readwrite".
// In case you want to support such an implementation, you can write:
// const transaction = db.transaction(["customers"], IDBTransaction.READ_WRITE);
在对新数据库执行任何操作之前,需要启动一个事务transaction。事务来自数据库对象,您必须指定希望事务跨越哪个对象存储。一旦进入事务内部,就可以访问保存数据和发出请求的对象存储。接下来,您需要决定是否要对数据库进行更改,还是只需要从数据库中读取数据。事务有三种可用的模式:只读(readonly)、读写(readwrite)和版本变更(versionchange)。
***注意:***通过在事务中使用正确的作用域和模式可以加速数据访问
- 在定义范围(scope)时,只指定需要的对象存储。通过这种方式,可以并发地运行具有不重叠作用域的多个事务。
- 只在必要时指定读写事务模式(readwrite)。可以并发地运行多个具有重叠作用域的只读事务,但是一个对象存储只能有一个读写事务。要了解更多信息。
事务方法:
transaction()**拥有两个参数,其中一个可选的,最后会返回一个事务对象。
- 第一个参数:类型数组,数组成员是对象存储名称,注意:数组为空时,事务将包括所有对象存储,不推荐这样做,后期空数组应该作为一种无效操作错误。
- 第二个参数:事务模式,参数值可选,只读(readonly)、读写(readwrite)和版本变更(versionchange)。注意:如果不传参数默认为只读模式
事务生命周期:
事务与事件循环紧密相连。如果您创建一个事务并返回到事件循环而不使用它,那么该事务将变为非活动状态。保持事务活动的唯一方法是对其发出请求。当请求完成时,您将获得一个DOM事件,并且假设请求成功,您将有另一个机会在回调期间扩展事务。如果没有扩展事务就返回事件循环,则事务将变为非活动状态,依此类推。只要有挂起的请求,事务就保持活动状态。事务生命周期非常简单,但可能需要一点时间来适应。再举几个例子也会有所帮助。如果你开始看到TRANSACTION_INACTIVE_ERR错误代码,那么你就把事情搞砸了。
事务可以接收三种不同类型的DOM事件:错误(error)、中止(abort)和完成(complete)。我们已经讨论了错误事件冒泡的方式,因此事务从它生成的任何请求中接收错误事件。这里更微妙的一点是,错误的默认行为是中止发生错误的事务。除非先在错误事件上调用stopPropagation(),然后再执行其他操作来处理错误,否则整个事务将回滚。这种设计迫使您考虑和处理错误,但您总是可以添加一个捕获错误处理程序。
1)数据库添加数据
// Do something when all the data is added to the database.
transaction.oncomplete = (event) => {
console.log("All done!");
};
transaction.onerror = (event) => {
// Don't forget to handle errors!
};
const objectStore = transaction.objectStore("customers");
customerData.forEach((customer) => {
const request = objectStore.add(customer);
request.onsuccess = (event) => {
// event.target.result === customer.ssn;
};
});
调用add()生成的请求的结果是所添加值的键。所以在这种情况下,它应该等于所添加对象的ssn属性,因为对象存储使用ssn属性作为键路径。注意,add()函数要求数据库中不存在具有相同键的对象。如果您试图修改一个现有的条目,或者您不关心是否已经存在一个条目,那么您可以使用put()函数,如下面的更新数据库中的条目部分所示。
2)数据库删除数据
const request = db
.transaction(["customers"], "readwrite")
.objectStore("customers")
.delete("444-44-4444");
request.onsuccess = (event) => {
// It's gone!
};
3)数据库获取数据
4)更新数据库中的条目
5)使用游标
6)使用索引
7)指定游标的范围和方向
